Содержание
Создание коллектора
Коллектор состоит из двух частей: одна часть создается внутри веб-интерфейса KUMA, а другая устанавливается на сервере сетевой инфраструктуры, предназначенном для получения событий.
Действия в веб-интерфейсе KUMA
Создание коллектора в веб-интерфейсе KUMA производится с помощью мастера установки, в процессе выполнения которого необходимые ресурсы объединяются в набор ресурсов для коллектора, а по завершении мастера на основе этого набора ресурсов автоматически создается и сам сервис.
Чтобы создать коллектор в веб-интерфейсе KUMA,
Запустите мастер установки коллектора:
- В веб-интерфейсе KUMA в разделе Ресурсы нажмите на кнопку Подключить источник.
- В веб-интерфейсе KUMA в разделе Ресурсы → Коллекторы нажмите на кнопку Добавить коллектор.
В результате выполнения шагов мастера в веб-интерфейсе KUMA создается сервис коллектора.
В набор ресурсов для коллектора объединяются следующие ресурсы:
- коннектор;
- нормализатор (как минимум один);
- фильтры (при необходимости);
- правила агрегации (при необходимости);
- правила обогащения (при необходимости);
- точки назначения (как правило, две: задается отправка событий в коррелятор и хранилище).
Эти ресурсы можно подготовить заранее, а можно создать в процессе выполнения мастера установки.
Действия на сервере коллектора KUMA
При установке коллектора на сервер, предназначенный для получения событий, требуется запустить команду, которая отображается на последнем шаге мастера установки. При установке необходимо указать идентификатор, автоматически присвоенный сервису в веб-интерфейсе KUMA, а также используемый для связи порт.
Проверка установки
После создания коллектора рекомендуется убедиться в правильности его работы.
Запуск мастера установки коллектора
Коллектор состоит из двух частей: одна часть создается внутри веб-интерфейса KUMA, а другая устанавливается на сервере сетевой инфраструктуры, предназначенной для получения событий. В мастере установки создается первая часть коллектора.
Чтобы запустить мастер установки коллектора:
- В веб-интерфейсе KUMA в разделе Ресурсы нажмите Подключить источник.
- В веб-интерфейсе KUMA в разделе Ресурсы → Коллекторы нажмите Добавить коллектор.
Следуйте указаниям мастера.
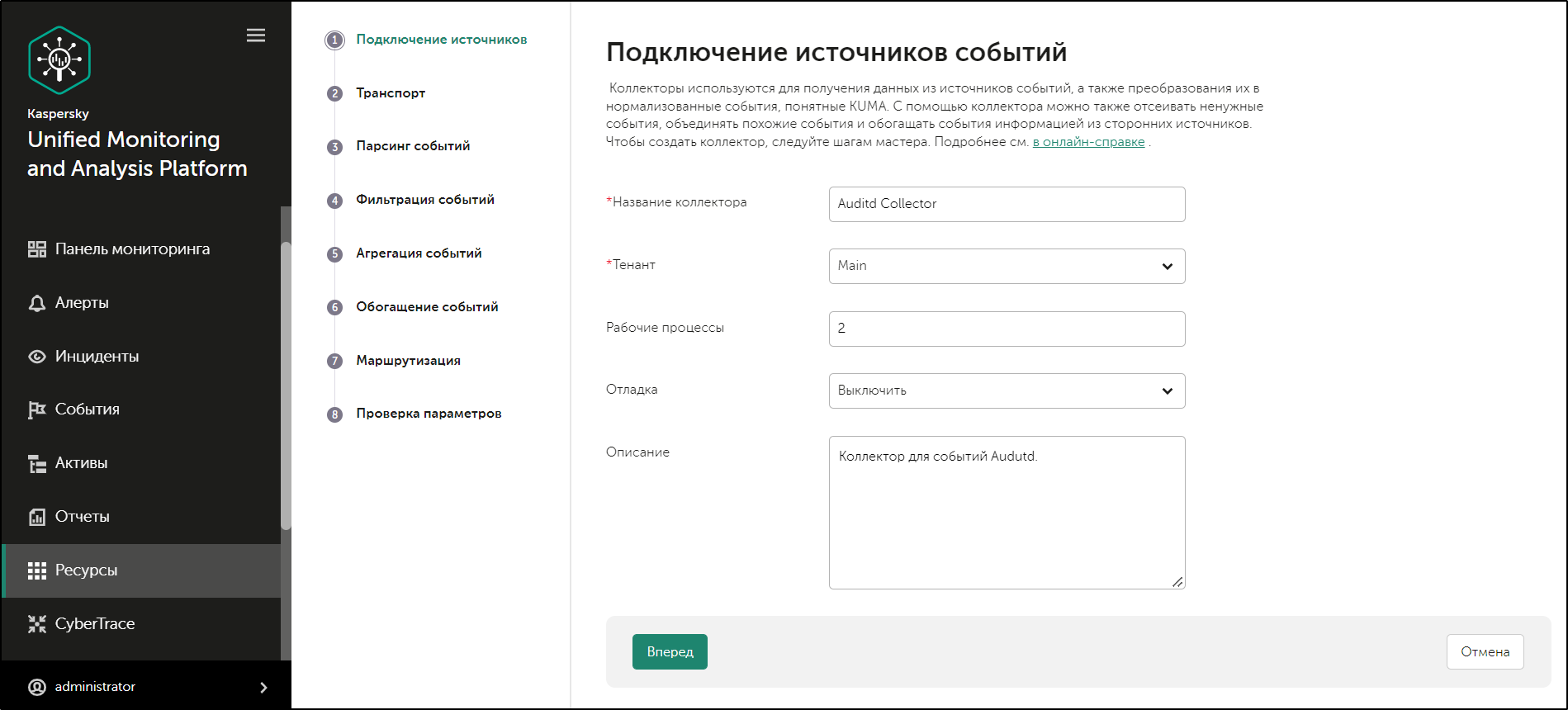
Мастер Подключения источников событий
Шаги мастера, кроме первого и последнего, можно выполнять в произвольном порядке. Переключаться между шагами можно с помощью кнопок Вперед и Назад, а также нажимая на названия шагов в левой части окна.
По завершении мастера в веб-интерфейсе KUMA в разделе Ресурсы → Коллекторы создается набор ресурсов для коллектора, а в разделе Ресурсы → Активные сервисы добавляется сервис коллектора.
Шаг 1. Подключение источников событий
Это обязательный шаг мастера установки. На этом шаге указываются основные параметры коллектора: название и тенант, которому он будет принадлежать.
Чтобы задать основные параметры коллектора:
- В поле Название коллектора введите уникальное имя создаваемого сервиса. Название должно содержать от 1 до 128 символов в кодировке Unicode.
При создании некоторых типов коллекторов вместе с ними автоматически создаются агенты, имеющие название "agent: <Название коллектора>, auto created". Если такой агент уже создавался ранее и не был удален, то коллектор с названием <Название коллектора> невозможно будет создать. В такой ситуации необходимо или указать другое название коллектора, или удалить ранее созданный агент.
- В раскрывающемся списке Тенант выберите тенант, которому будет принадлежать коллектор. От выбора тенанта зависит, какие ресурсы будут доступны при его создании.
Если вы с какого-либо последующего шага мастера установки вернетесь в это окно и выберите другой тенант, вам потребуется вручную изменить все ресурсы, которые вы успели добавить в сервис. В сервис можно добавлять только ресурсы из выбранного и общего тенантов.
- В поле Рабочие процессы при необходимости укажите количество процессов, которые может одновременно запускать сервис. По умолчанию количество рабочих процессов соответствует количеству vCPU сервера, на котором установлен сервис.
- При необходимости с помощью раскрывающегося списка Отладка включите логирование операций сервиса.
Сообщения об ошибках сервиса коллектора помещаются в журнал, даже если режим отладки выключен. Журнал можно просмотреть на машине, где установлен коллектор, в директории /opt/kaspersky/kuma/collector/<идентификатор коллектора>/log/collector.
- В поле Описание можно добавить описание сервиса: до 256 символов в кодировке Unicode.
Основные параметры коллектора будут заданы. Перейдите к следующему шагу мастера установки.
В началоШаг 2. Транспорт
Это обязательный шаг мастера установки. В закладке мастера установки Транспорт следует выбрать или создать коннектор, в параметрах которого будет определено, откуда сервис коллектора должен получать события.
Чтобы добавить в набор ресурсов существующий коннектор,
выберите в раскрывающемся списке Коннектор название нужного коннектора.
В закладке мастера установки Транспорт отобразятся параметры выбранного коннектора. Выбранный коннектор можно открыть для редактирования в новой вкладке браузера с помощью кнопки  .
.
Чтобы создать новый коннектор:
- Выберите в раскрывающемся списке Коннектор пункт Создать.
- В раскрывающемся списке Тип выберите тип коннектора и укажите его параметры в закладках Основные параметры и Дополнительные параметры. Набор доступных параметров зависит от выбранного типа коннектора:
При использовании типа коннектора tcp или udp на этапе нормализации в поле событий DeviceAddress, если оно пустое, будут записаны IP-адреса устройств, с которых были получены события.
При использовании типа коннектора wmi или wec будут автоматически созданы агенты для приема событий Windows.
Рекомендуется использовать кодировку по умолчанию (то есть UTF-8) и применять другие параметры только при получении в полях событий битых символов.
Для настройки коллекторов KUMA на прослушивание портов с номерами меньше 1000 сервис нужного коллектора необходимо запускать с правами root. Для этого после установки коллектора в его конфигурационный файл systemd в раздел [Service] требуется дописать строку
AmbientCapabilities=CAP_NET_BIND_SERVICE.
Systemd-файл располагается в директории /usr/lib/systemd/system/kuma-collector-<идентификатор коллектора>.service.
Коннектор добавлен в набор ресурсов коллектора. Созданный коннектор доступен только в этом наборе ресурсов и не отображается в разделе веб-интерфейса Ресурсы → Коннекторы.
Перейдите к следующему шагу мастера установки.
В началоШаг 3. Парсинг событий
Это обязательный шаг мастера установки. В закладке мастера установки Парсинг событий следует выбрать или создать нормализатор, в параметрах которого будут определены правила преобразования "сырых" событий в нормализованные. В нормализатор можно добавить несколько правил парсинга событий, реализуя таким образом сложную логику обработки событий.
При создании нового нормализатора в мастере установки по умолчанию он будет сохранен в наборе ресурсов для коллектора и не сможет быть использован в других коллекторах. С помощью флажка Сохранить нормализатор вы можете создать нормализатор в виде отдельного ресурса.
Если вы, меняя параметры набора ресурсов коллектора, измените или удалите преобразования в подключенном к нему нормализаторе, правки не сохранятся, а сам нормализатор может быть поврежден. При необходимости изменить преобразования в нормализаторе, который уже является частью сервиса, вносите правки непосредственно в нормализатор в разделе веб-интерфейса Ресурсы → Нормализаторы.
Добавление нормализатора
Чтобы добавить в набор ресурсов существующий нормализатор:
- Нажмите на кнопку Добавить парсинг событий.
Откроется окно Парсинг событий с параметрами нормализатора и активной закладкой Схема нормализации.
- В раскрывающемся списке Нормализатор выберите нужный нормализатор.
В окне Парсинг событий отобразятся параметры выбранного нормализатора. Выбранный нормализатор можно открыть для редактирования в новой вкладке браузера с помощью кнопки
. - Нажмите ОК.
В закладке мастера установки Парсинг событий отображается нормализатор в виде темного кружка. Можно нажать на кружок, чтобы открыть параметры нормализатора для редактирования. При наведении на кружок отображается значок плюса: при нажатии на него можно добавить дополнительные нормализаторы (см. ниже).
Чтобы создать новый нормализатор:
- Выберите в раскрывающемся списке Нормализатор пункт Создать.
Откроется окно Парсинг событий с параметрами нормализатора и активной закладкой Схема нормализации.
- Если хотите сохранить нормализатор в качестве отдельного ресурса, установите флажок Сохранить нормализатор. По умолчанию флажок снят.
- Введите в поле Название уникальное имя для нормализатора. Название должно содержать от 1 до 128 символов в кодировке Unicode.
- В раскрывающемся списке Метод парсинга выберите тип получаемых событий. В зависимости от выбора можно будет воспользоваться преднастроенными правилами сопоставления полей событий или же задать свои собственные правила. При выборе некоторых методов парсинга могут стать доступны дополнительные параметры, требуемые для заполнения.
Доступные методы парсинга:
- json
- cef
- regexp
Этот метод парсинга используется для создания собственных правил обработки данных в формате с использованием регулярных выражений.
В поле блока параметров Нормализация необходимо добавить регулярное выражение (синтаксис RE2) c именованными группами захвата: имя группы и ее значение будут считаться полем и значением "сырого" события, которое можно будет преобразовать в поле события формата KUMA.
Чтобы добавить правила обработки событий:
- Скопируйте в поле Примеры событий пример данных, которые вы хотите обработать. Это необязательный, но рекомендуемый шаг.
- В поле блока параметров Нормализация добавьте регулярное выражение c именованными группами захвата в синтаксисе RE2, например "(?P<name>regexp)". Регулярное выражение, добавленное в параметр Нормализация, должно полностью совпадать с событием. Также при разработке регулярного выражения рекомендуется использовать специальные символы, обозначающие начало и конец текста: ^, $.
Можно добавить несколько регулярных выражений с помощью кнопки Добавить регулярное выражение. При необходимости удалить регулярное выражение, воспользуйтесь кнопкой
 .
. - Нажмите на кнопку Перенести названия полей в таблицу.
Имена групп захвата отображаются в столбце Поле KUMA таблицы Сопоставление. Теперь в столбце напротив каждой группы захвата можно выбрать соответствующее ей поле KUMA или, если вы именовали группы захвата в соответствии с форматом CEF, можно воспользоваться автоматическим сопоставлением CEF, поставив флажок Использовать синтаксис CEF при нормализации.
Правила обработки событий добавлены.
- syslog
- csv
- kv
- xml
Этот метод парсинга используется для обработки данных в формате XML, в которых каждый объект, включая его вложенные объекты, занимает одну строку файла. Файлы обрабатываются построчно.
При выборе этого метода в блоке параметров Атрибуты XML можно указать ключевые атрибуты, которые следует извлекать из тегов. Если в структуре XML в одном тэге есть атрибуты с разными значениями, можно определить нужное значение, указав ключ к нему в столбце Исходные данные таблицы Сопоставление.
Чтобы добавить ключевые атрибуты XML,
Нажмите на кнопку Добавить поле и в появившемся окне укажите путь к нужному атрибуту.
Можно добавить несколько атрибутов. Атрибуты можно удалить по одному с помощью значка с крестиком или все сразу с помощью кнопки Сбросить.
Если ключевые атрибуты XML не указаны, при сопоставлении полей уникальный путь к значению XML будет представлен последовательностью тегов.
Нумерация тегов
Начиная с версии KUMA 2.1.3 доступна Нумерация тегов. Опция предназначена для выполнения автоматической нумерации тегов в событиях в формате XML, чтобы можно было распарсить событие с одинаковыми тэгами или неименованными тэгами, такими как <Data>.
В качестве примера мы используем функцию Нумерация тегов для нумерации тегов атрибута EventData события Microsoft Windows PowerShell event ID 800.
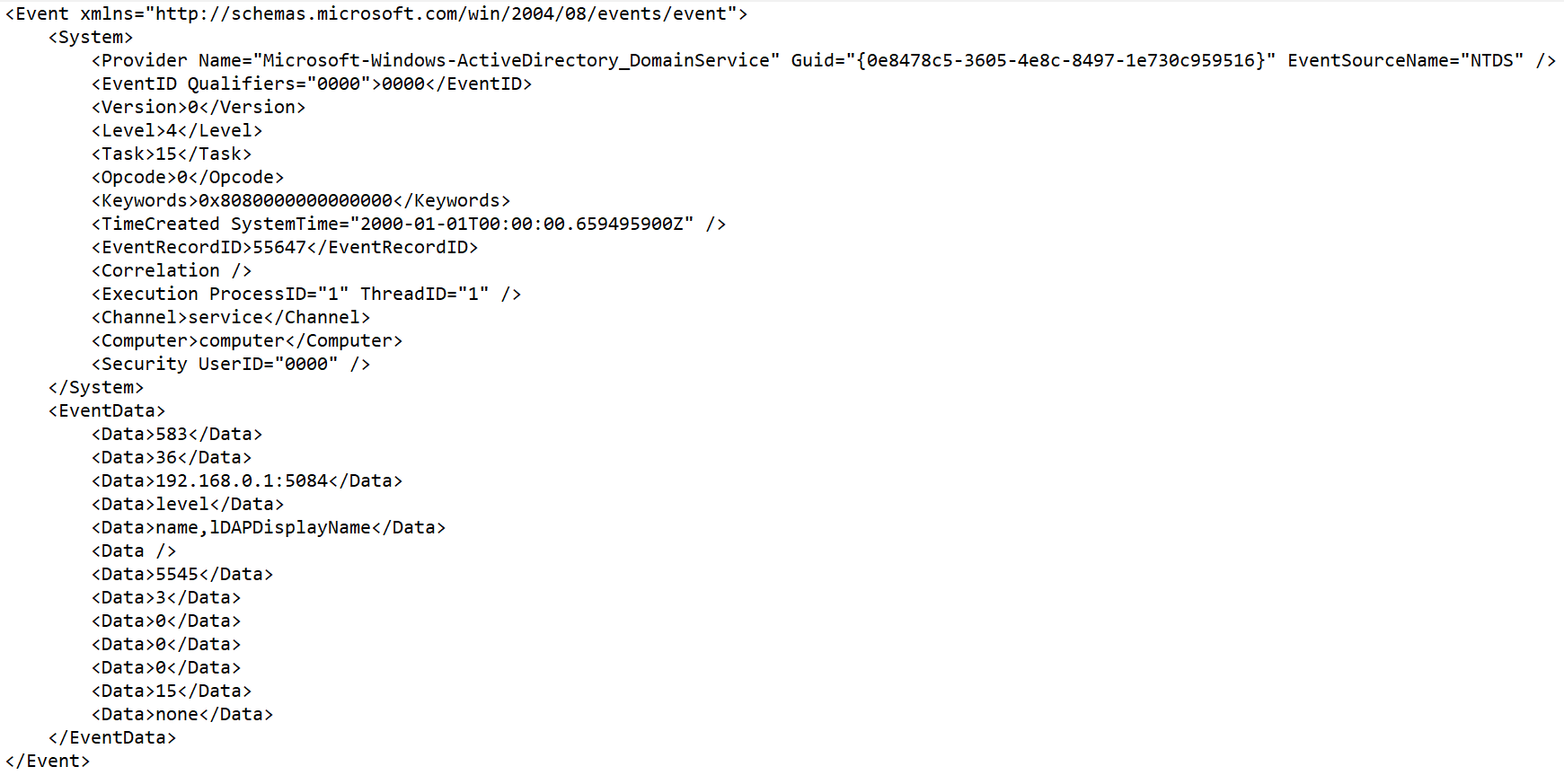
Чтобы выполнить парсинг таких событий необходимо:
- Настроить нумерацию тегов.
- Настроить мапинг данных для пронумерованных тегов с полями события KUMA.
Одновременное применение функций Атрибуты XML и Нумерация тегов приведёт к некорректной работе нормализатора. Если атрибут содержит неименованные тэги или одинаковые тэги, мы рекомендуем использовать функцию Нумерация тегов. Если атрибут содержит только именованные тэги, используйте Атрибуты XML.
Чтобы настроить парсинг событий с тэгами, содержащими одинаковое название или тэги без названия:
- Создайте новый нормализатор или откройте существующий нормализатор для редактирования.
- В окне нормализатора Основной парсинг событий в раскрывающемся списке Метод парсинга выберите значение xml и в поле Нумерация тегов нажмите Добавить поле.
В появившемся поле укажите полный путь к тэгу, элементам которого следует присвоить порядковый номер. Например, Event.EventData.Data. Первый номер, который будет присвоен тэгу – 0. Если тэг пустой, например, <Data />, ему также будет присвоен порядковый номер.
- Чтобы настроить мапинг данных, в группе параметров Сопоставление нажмите Добавить строку и выполните следующие действия:
- В появившейся строке в поле Исходные данные укажите полный путь к тэгу и его индекс. Для события Microsoft Windows из примера выше полный путь с индексами будет выглядеть следующим образом:
- Event.EventData.Data.0
- Event.EventData.Data.1
- Event.EventData.Data.2 и так далее
- В раскрывающемся списке Поле KUMA выберите поле в событии KUMA, в которое попадет значение из пронумерованного тэга после выполнения парсинга.
- В появившейся строке в поле Исходные данные укажите полный путь к тэгу и его индекс. Для события Microsoft Windows из примера выше полный путь с индексами будет выглядеть следующим образом:
- Чтобы сохранить изменения:
- Если вы создали новый нормализатор, нажмите Сохранить.
- Если вы редактировали существующий нормализатор, нажмите Обновить параметры в коллекторе, к которому привязан нормализатор.
Настройка парсинга завершена.
- netflow5
- netflow9
- sflow5
- ipfix
- sql – этот метод становится доступным, только при использовании коннектора типа sql
- В раскрывающемся списке Сохранить исходное событие укажите, надо ли сохранять исходное "сырое" событие во вновь созданном нормализованном событии. Доступные значения:
- Не сохранять – не сохранять исходное событие. Это значение используется по умолчанию.
- При возникновении ошибок – сохранять исходное событие в поле
Rawнормализованного события, если в процессе парсинга возникли ошибки. Это значение удобно использовать при отладке сервиса: в этом случае появление у событий непустого поляRawбудет являться признаком неполадок. - Всегда – сохранять сырое событие в поле
Rawнормализованного события.
- В раскрывающемся списке Сохранить дополнительные поля выберите, требуется ли сохранять поля исходного события в нормализованном событии, если для них не были настроены правила сопоставления (см. ниже). Данные сохраняются в поле события Extra. По умолчанию поля не сохраняются.
- Скопируйте в поле Примеры событий пример данных, которые вы хотите обработать. Это необязательный, но рекомендуемый шаг.
- В таблице Сопоставление настройте сопоставление полей исходного события с полями события в формате KUMA:
- В столбце Исходные данные укажите название поля исходного события, которое вы хотите преобразовать в поле события KUMA.
Если рядом с названиями полей в столбце Исходные данные нажать на кнопку
 , откроется окно Преобразование, в котором с помощью кнопки Добавить преобразование можно создать правила изменения исходных данных перед тем, как они будут записаны в поля событий KUMA.
, откроется окно Преобразование, в котором с помощью кнопки Добавить преобразование можно создать правила изменения исходных данных перед тем, как они будут записаны в поля событий KUMA.В окне Преобразования добавленные правила можно менять местами, перетягивая их за значок
 , а также удалять с помощью значка
, а также удалять с помощью значка  .
. - В столбце Поле KUMA в раскрывающемся списке выберите требуемое поле события KUMA. Поля можно искать, вводя в поле их названия.
- Если название поля события KUMA, выбранного на предыдущем шаге, начинается с
DeviceCustom*иFlex*, в поле Подпись можно добавить уникальную пользовательскую метку.
Новые строки таблицы можно добавлять с помощью кнопки Добавить строку. Строки можно удалять по отдельности с помощью кнопки
или все сразу с помощью кнопки Очистить все.Если вы загрузили данные в поле Примеры событий, в таблице отобразится столбец Примеры с примерами значений, переносимых из поля исходного события в поле события KUMA.
- В столбце Исходные данные укажите название поля исходного события, которое вы хотите преобразовать в поле события KUMA.
- Нажмите ОК.
В закладке мастера установки Парсинг событий отображается нормализатор в виде темного кружка. Можно нажать на кружок, чтобы открыть его параметры для редактирования. При наведении на кружок отображается значок плюса: при нажатии на него можно добавить дополнительные правила парсинга событий (см. ниже).
Обогащение нормализованного события дополнительными данными
В только что созданные нормализованные события можно добавлять дополнительные данные, создавая в нормализаторе правила обогащения. Эти правила хранятся в нормализаторе, в котором они были созданы. Правил обогащения может быть несколько.
Чтобы добавить правила обогащения в нормализатор:
- Выберите основное или дополнительное правило нормализации, а затем в открывшемся окне перейдите на закладку Обогащение.
- Нажмите на кнопку Добавить обогащение.
Появится блок параметров правила обогащения. Блок параметров можно удалить с помощью кнопки
. - В раскрывающемся списке Тип источника выберите тип обогащения. В зависимости от выбранного типа отобразятся дополнительные параметры, которые также потребуется заполнить.
Доступные типы источников обогащения:
- константа
- словарь
- таблица
Этот тип обогащения используется, если в поле события необходимо добавить значение из словаря типа Таблица.
При выборе этого типа обогащения в раскрывающемся списке Название словаря необходимо выбрать словарь, из которого будут браться значения, а в блоке параметров Ключевые поля с помощью кнопки Добавить поле требуется выбрать поля события, значения которых будут использоваться для выбора записи словаря.
Также в таблице Сопоставление необходимо настроить, из каких полей словаря и в какие поля события будут передаваться данные:
- В столбце Поле словаря необходимо выбрать поле словаря. Доступные поля зависят от выбранного ресурса словаря.
- В столбце Поле KUMA необходимо выбрать поле события, в которое следует записать значение. Для некоторых выбранных полей (
*custom*и*flex*) в столбце Подпись можно задать название для помещаемых в них данных.
Новые строки в таблицу можно добавлять с помощью кнопки Добавить элемент. Столбцы можно удалить с помощью кнопки
. - событие
Этот тип обогащения используется, если в поле события необходимо записать значение другого поля события. Параметры этого типа обогащения:
- В раскрывающемся списке Целевое поле выберите поле события KUMA, в которое следует поместить данные.
- В раскрывающемся списке Исходное поле выберите поле события, значение которого будет записано в целевое поле.
- Если нажать на кнопку , откроется окно Преобразование, в котором с помощью кнопки Добавить преобразование можно создать правила изменения исходных данных перед тем, как они будут записаны в поля событий KUMA.
- шаблон
- В раскрывающемся списке Целевое поле выберите поле события KUMA, в которое следует поместить данные.
Этот параметр недоступен для типа источника обогащения таблица.
- Нажмите ОК.
В нормализатор, в выбранное правило парсинга, добавлены правила обогащения событий дополнительными данными.
Создание структуры правил нормализации событий
Для реализации сложной логики обработки событий в нормализатор можно добавить более одного правила парсинга событий. События передаются между правилами парсинга в зависимости от заданных условий. Последовательность создания правил парсинга имеет значение: событие обрабатывается последовательно и его путь отображается в виде стрелочек.
Чтобы создать дополнительное правило парсинга:
- Создайте нормализатор (см. выше).
Созданный номрализатор отобразится в окне в виде темного кружка.
- Наведите указатель мыши на кружок и нажмите на появившуюся кнопку со значком плюса.
- В открывшемся окне Дополнительный парсинг события задайте параметры дополнительного правила парсинга события:
- Закладка Условия дополнительной нормализации:
Если вы хотите отправлять в дополнительный нормализатор только события с определенным полем, укажите его в поле Поле, которое следует передать в нормализатор.
На этой закладке вы также можете определить другие условия, при выполнении которых событие будет поступать на дополнительный парсинг.
- Закладка Схема нормализации:
На этой закладке можно настроить правила обработки событий, по аналогии с параметрами основного нормализатора (см. выше). Параметр Сохранить исходное событие недоступен. В поле Примеры событий отображаются значения, указанные при создании начального нормализатора.
- Закладка Обогащение:
На этой закладке можно настроить правила обогащения событий (см. выше).
- Закладка Условия дополнительной нормализации:
- Нажмите ОК.
Дополнительное правило парсинга добавлено в нормализатор и отображается в виде темного блока, на котором указаны условия, при котором это правило будет задействовано. Параметры дополнительного правила парсинга можно изменить, нажав на него. Если навести указатель мыши на дополнительное правило парсинга, отобразится кнопка со значком плюса, с помощью которой можно создать новое дополнительное правило парсинга. С помощью кнопки со значком корзины нормализатор можно удалить.
В верхнем правом углу окна располагается окно поиска, где можно искать правила парсинга по названию.
Перейдите к следующему шагу мастера установки.
В началоШаг 4. Фильтрация событий
Это необязательный шаг мастера установки. В закладке мастера установки Фильтрация событий можно выбрать или создать фильтр, в параметрах которого будут определены условия отбора событий. В коллектор можно добавить несколько фильтров. Фильтры можно менять местами, перетягивая их мышью за значок , и удалять. Фильтры объединены оператором И.
Чтобы добавить в набор ресурсов коллектора существующий фильтр,
Нажмите на кнопку Добавить фильтр и в раскрывающемся меню Фильтр выберите требуемый фильтр.
Чтобы добавить в набор ресурсов коллектора новый фильтр:
- Нажмите на кнопку Добавить фильтр и в раскрывающемся меню Фильтр выберите пункт Создать.
- Если хотите сохранить фильтр в качестве отдельного ресурса, установите флажок Сохранить фильтр. Это может оказаться полезным, если вы решите использовать один и тот же фильтр в разных сервисах. По умолчанию флажок снят.
- Если вы установили флажок Сохранить фильтр, в поле Название введите название для создаваемого фильтра. Название должно содержать от 1 до 128 символов в кодировке Unicode.
- В разделе Условия задайте условия, которым должны соответствовать отсеиваемые события:
- С помощью кнопки Добавить условие добавляются условия фильтра, можно выбрать два значения (левый и правый операнды) и назначить операцию, которую вы хотите выполнить с выбранными значениями. Результат операции – Истина (True) или Ложь (False).
- В раскрывающемся списке оператор необходимо выбрать функцию, которую должен выполнять фильтр.
В этом же раскрывающемся списке можно установить флажок без учета регистра, если требуется, чтобы оператор игнорировал регистр значений. Флажок игнорируется, если выбраны операторы InSubnet, InActiveList, InCategory, InActiveDirectoryGroup. По умолчанию флажок снят.
- В раскрывающихся списках Левый операнд и Правый операнд необходимо выбрать, откуда поступят данные, с которыми произведет действие фильтр. В результате выбора появляются дополнительные параметры, с помощью которых необходимо точно определить значение, которое будет передано в фильтр. Например, при выборе варианта активный лист потребуется указать название активного листа, ключ записи и поле ключа записи.
- С помощью раскрывающегося списка Если можно выбрать, требуется ли создать отрицательное условие фильтра.
Условие можно удалить с помощью кнопки
. - В раскрывающемся списке оператор необходимо выбрать функцию, которую должен выполнять фильтр.
- С помощью кнопки Добавить группу добавляются группы условий. Оператор И можно переключать между значениями И, ИЛИ, НЕ.
Группу условий можно удалить с помощью кнопки
. - С помощью кнопки Добавить фильтр в условия добавляются существующие фильтры, которые выбираются в раскрывающемся списке Выберите фильтр. В параметры вложенного фильтра можно перейти с помощью кнопки .
Вложенный фильтр можно удалить с помощью кнопки
.
- С помощью кнопки Добавить условие добавляются условия фильтра, можно выбрать два значения (левый и правый операнды) и назначить операцию, которую вы хотите выполнить с выбранными значениями. Результат операции – Истина (True) или Ложь (False).
Фильтр добавлен.
Перейдите к следующему шагу мастера установки.
В началоШаг 5. Агрегация событий
Это необязательный шаг мастера установки. В закладке мастера установки Агрегация событий можно выбрать или создать правила агрегации, в параметрах которого будут определены условия для объединения однотипных событий. В коллектор можно добавить несколько правил агрегации.
Чтобы добавить в набор ресурсов коллектора существующее правило агрегации,
Нажмите на кнопку Добавить правило агрегации и в раскрывающемся списке выберите Правило агрегации.
Чтобы добавить в набор ресурсов коллектора новое правило агрегации:
- Нажмите на кнопку Добавить правило агрегации и в раскрывающемся меню Правило агрегации выберите пункт Создать.
- В поле Название введите название для создаваемого правила агрегации. Название должно содержать от 1 до 128 символов в кодировке Unicode.
- В поле Предел событий укажите количество событий, которое должно быть получено, чтобы сработало правило агрегации и события были объединены. Значение по умолчанию:
100. - В поле Время ожидания событий укажите количество секунд, в течение которых коллектор получает события для объединения. По истечении этого срока правило агрегации срабатывает и создается новое агрегационное событие. Значение по умолчанию:
60. - В разделе Группирующие поля с помощью кнопки Добавить поле выберите поля, по которым будут определяться однотипные события. Выбранные события можно удалять с помощью кнопок со значком крестика.
- В разделе Уникальные поля с помощью кнопки Добавить поле можно выбрать поля, при наличии которых коллектор исключит событие из процесса агрегации даже при наличии полей, указанных в разделе Группирующие поля. Выбранные события можно удалять с помощью кнопок со значком крестика.
- В разделе Поля суммы с помощью кнопки Добавить поле можно выбрать поля, значения которых будут просуммированы в процессе агрегации. Выбранные события можно удалять с помощью кнопок со значком крестика.
- В разделе Фильтр можно задать условия определения событий, которые будут обрабатываться этим ресурсом. В раскрывающемся списке можно выбрать существующий фильтр или Создать новый фильтр.
- В раскрывающемся списке Фильтр выберите Создать.
- Если вы хотите сохранить фильтр в качестве отдельного ресурса, установите флажок Сохранить фильтр.
В этом случае вы сможете использовать созданный фильтр в разных сервисах.
По умолчанию флажок снят.
- Если вы установили флажок Сохранить фильтр, в поле Название введите название для создаваемого ресурса фильтра. Название должно содержать от 1 до 128 символов в кодировке Unicode.
- В блоке параметров Условия задайте условия, которым должны соответствовать события:
- Нажмите на кнопку Добавить условие.
- В раскрывающихся списках Левый операнд и Правый операнд укажите параметры поиска.
В зависимости от источника данных, выбранного в поле Правый операнд, могут отобразиться поля дополнительных параметров, с помощью которых вам нужно определить значение, которое будет передано в фильтр. Например, при выборе варианта активный лист потребуется указать название активного листа, ключ записи и поле ключа записи.
- В раскрывающемся списке оператор выберите нужный вам оператор.
- При необходимости установите флажок без учета регистра. В этом случае оператор игнорирует регистр значений.
Действие флажка не распространяется на операторы InSubnet, InActiveList, InCategory, InActiveDirectoryGroup.
По умолчанию флажок снят.
- Если вы хотите добавить отрицательное условие, в раскрывающемся списке Если выберите Если не.
- Вы можете добавить несколько условий или группу условий.
- Если вы добавили несколько условий или групп условий, выберите условие отбора (и, или, не), нажав на кнопку И.
- Если вы хотите добавить уже существующие фильтры, которые выбираются в раскрывающемся списке Выберите фильтр, нажмите на кнопку Добавить фильтр.
Параметры вложенного фильтра можно просмотреть, нажав на кнопку
.
Правило агрегации добавлено. Его можно удалить с помощью кнопки .
Перейдите к следующему шагу мастера установки.
В началоШаг 6. Обогащение событий
Это необязательный шаг мастера установки. В закладке мастера установки Обогащение событий можно указать, какими данными и из каких источников следует дополнить обрабатываемые коллектором события. События можно обогащать данными, полученными с помощью правил обогащения или с помощью LDAP.
Обогащение с помощью правил обогащения
Правил обогащения может быть несколько. Их можно добавить с помощью кнопки Добавить обогащение или удалить с помощью кнопки . Можно использовать существующие правила обогащения или же создать правила непосредственно в мастере установки.
Чтобы добавить в набор ресурсов существующее правило обогащения:
- Нажмите Добавить обогащение.
Откроется блок параметров правил обогащения.
- В раскрывающемся списке Правило обогащения выберите нужный ресурс.
Правило обогащения добавлено в набор ресурсов для коллектора.
Чтобы создать в наборе ресурсов новое правило обогащения:
- Нажмите Добавить обогащение.
Откроется блок параметров правил обогащения.
- В раскрывающемся списке Правило обогащения выберите Создать.
- В раскрывающемся списке Тип источника данных выберите, откуда будут поступать данные для обогащения, и заполните относящиеся к нему параметры:
- константа
- словарь
- событие
- шаблон
- dns
- cybertrace
Этот тип обогащения используется для добавления в поля события сведений из потоков данных CyberTrace.
Доступные параметры:
- URL (обязательно) – в этом поле можно указать URL сервера CyberTrace, которому вы хотите отправлять запросы.
- Количество подключений – максимальное количество подключений к серверу CyberTrace, которые может одновременно установить KUMA. Значение по умолчанию равно количеству vCPU сервера, на котором установлено Ядро KUMA.
- Запросов в секунду – максимальное количество запросов к серверу в секунду. Значение по умолчанию:
1000. - Время ожидания – время ожидания отклика от сервера CyberTrace в секундах. Значение по умолчанию:
30. - Сопоставление (обязательно) – этот блок параметров содержит таблицу сопоставления полей событий KUMA с типами индикаторов CyberTrace. В столбце Поле KUMA указаны названия полей событий KUMA, а в столбце Индикатор CyberTrace указаны типы индикаторов CyberTrace.
Доступные типы индикаторов CyberTrace:
- ip
- url
- hash
В таблице сопоставления требуется указать как минимум одну строку. С помощью кнопки Добавить строку можно добавить строку, а с помощью кнопки
– удалить.
- часовой пояс
- геоданные
Этот тип обогащения используется для добавления в поля событий сведений о географическом расположении IP-адресов. Подробнее о привязке IP-адресов к географическим данным.
При выборе этого типа в блоке параметров Сопоставление геоданных с полями события необходимо указать, из какого поля события будет считан IP-адрес, а также выбрать требуемые атрибуты геоданных и определить поля событий, в которые геоданные будут записаны:
- В раскрывающемся списке Поле события с IP-адресом выберите поле события, из которого считывается IP-адрес. По этому IP-адресу будет произведен поиск соответствий по загруженным в KUMA геоданным.
С помощью кнопки Добавить поле события с IP-адресом можно указать несколько полей события с IP-адресами, по которым требуется обогащение геоданными. Удалить добавленные таким образом поля событий можно с помощью кнопки Удалить поле события с IP-адресом.
При выборе полей события
SourceAddress,DestinationAddressиDeviceAddressстановится доступна кнопка Применить сопоставление по умолчанию. С ее помощью можно добавить преднастроенные пары соответствий атрибутов геоданных и полей события. - Для каждого поля события, откуда требуется считать IP-адрес, выберите тип геоданных и поле события, в которое следует записать геоданные.
С помощью кнопки Добавить атрибут геоданных вы можете добавить пары полей Атрибут геоданных – Поле события для записи. Так вы можете настроить запись разных типов геоданных одного IP-адреса в разные поля события. Пары полей можно удалить с помощью значка
 .
.- В поле Атрибут геоданных выберите, какие географические сведения, соответствующие считанному IP-адресу, необходимо записать в событие. Доступные атрибуты геоданных: Страна, Регион, Город, Долгота, Широта.
- В поле Поле события для записи выберите поле события, в которое необходимо записать выбранный атрибут геоданных.
Вы можете записать одинаковые атрибуты геоданных в разные поля событий. Если вы настроите запись нескольких атрибутов геоданных в одно поле события, событие будет обогащено последним по очереди сопоставлением.
- В раскрывающемся списке Поле события с IP-адресом выберите поле события, из которого считывается IP-адрес. По этому IP-адресу будет произведен поиск соответствий по загруженным в KUMA геоданным.
- С помощью раскрывающегося списка Отладка укажите, следует ли включить логирование операций сервиса. По умолчанию логирование выключено.
- В разделе Фильтр можно задать условия определения событий, которые будут обрабатываться ресурсом правила обогащения. В раскрывающемся списке можно выбрать существующий фильтр или Создать новый фильтр.
- В раскрывающемся списке Фильтр выберите Создать.
- Если вы хотите сохранить фильтр в качестве отдельного ресурса, установите флажок Сохранить фильтр.
В этом случае вы сможете использовать созданный фильтр в разных сервисах.
По умолчанию флажок снят.
- Если вы установили флажок Сохранить фильтр, в поле Название введите название для создаваемого ресурса фильтра. Название должно содержать от 1 до 128 символов в кодировке Unicode.
- В блоке параметров Условия задайте условия, которым должны соответствовать события:
- Нажмите на кнопку Добавить условие.
- В раскрывающихся списках Левый операнд и Правый операнд укажите параметры поиска.
В зависимости от источника данных, выбранного в поле Правый операнд, могут отобразиться поля дополнительных параметров, с помощью которых вам нужно определить значение, которое будет передано в фильтр. Например, при выборе варианта активный лист потребуется указать название активного листа, ключ записи и поле ключа записи.
- В раскрывающемся списке оператор выберите нужный вам оператор.
- При необходимости установите флажок без учета регистра. В этом случае оператор игнорирует регистр значений.
Действие флажка не распространяется на операторы InSubnet, InActiveList, InCategory, InActiveDirectoryGroup.
По умолчанию флажок снят.
- Если вы хотите добавить отрицательное условие, в раскрывающемся списке Если выберите Если не.
- Вы можете добавить несколько условий или группу условий.
- Если вы добавили несколько условий или групп условий, выберите условие отбора (и, или, не), нажав на кнопку И.
- Если вы хотите добавить уже существующие фильтры, которые выбираются в раскрывающемся списке Выберите фильтр, нажмите на кнопку Добавить фильтр.
Параметры вложенного фильтра можно просмотреть, нажав на кнопку
.
В набор ресурсов для коллектора добавлено новое правило обогащения.
Обогащение с помощью LDAP
Чтобы включить обогащение с помощью LDAP:
- Нажмите Добавить сопоставление с учетными записями LDAP.
Откроется блок параметров обогащения с помощью LDAP.
- В блоке параметров Сопоставление с учетными записями LDAP с помощью кнопки Добавить домен укажите домен учетных записей. Доменов можно указать несколько.
- В таблице Обогащение полей KUMA задайте правила сопоставления полей KUMA с атрибутами LDAP:
- В столбце Поле KUMA укажите поле события KUMA, данные из которого следует сравнить с атрибутом LDAP.
- В столбце LDAP-атрибут, укажите атрибут, с которым необходимо сравнить поле события KUMA. Раскрывающийся список содержит стандартные атрибуты и может быть дополнен пользовательскими атрибутами.
- В столбце Поле для записи данных укажите, в какое поле события KUMA следует поместить идентификатор пользовательской учетной записи, импортированной из LDAP, если сопоставление было успешно.
С помощью кнопки Добавить строку в таблицу можно добавить строку, а с помощью кнопки
– удалить. С помощью кнопки Применить сопоставление по умолчанию можно заполнить таблицу сопоставления стандартными значениями.
В блок ресурсов для коллектора добавлены правила обогащения события данными, полученными из LDAP.
При добавлении в существующий коллектор обогащения с помощью LDAP или изменении параметров обогащения требуется остановить и запустить сервис снова.
Перейдите к следующему шагу мастера установки.
В началоШаг 7. Маршрутизация
Это необязательный шаг мастера установки. В закладке мастера установки Маршрутизация можно выбрать или создать точки назначения, в параметрах которых будут определено, куда следует перенаправлять обработанные коллектором события. Обычно события от коллектора перенаправляются в две точки: в коррелятор для анализа и поиска угроз; в хранилище для хранения, а также чтобы обработанные события можно было просматривать позднее. При необходимости события можно отправлять в другие места. Точек назначения может быть несколько.
Чтобы добавить в набор ресурсов коллектора существующую точку назначения:
- В раскрывающемся списке Добавить точку назначения выберите тип точки назначения, которую вы хотите добавить:
- Выберите Хранилище, если хотите настроить отправку обработанных событий в хранилище.
- Выберите Коррелятор, если хотите настроить отправку обработанных событий в коррелятор.
- Выберите Другое, если хотите отправлять события в другие места.
К этому типу относятся также сервисы коррелятора и хранилища, созданные в предыдущих версиях программы.
Открывается окно Добавить точку назначения, где можно указать параметры пересылки событий.
- В раскрывающемся списке Точка назначения выберите нужную точку назначения.
Название окна меняется на Изменить точку назначения, параметры выбранного ресурса отображаются в окне. Параметры точки назначения можно открыть для редактирования в новой вкладке браузера с помощью кнопки
. - Нажмите Сохранить.
Выбранная точка назначения отображается в закладке мастера установки. Точку назначения можно удалить из набора ресурсов, выбрав ее и в открывшемся окне нажав Удалить.
Чтобы добавить в набор ресурсов коллектора новую точку назначения:
- В раскрывающемся списке Добавить точку назначения выберите тип точки назначения, которую вы хотите добавить:
- Выберите Хранилище, если хотите настроить отправку обработанных событий в хранилище.
- Выберите Коррелятор, если хотите настроить отправку обработанных событий в коррелятор.
- Выберите Другое, если хотите отправлять события в другие места.
К этому типу относятся также сервисы коррелятора и хранилища, созданные в предыдущих версиях программы.
Открывается окно Добавить точку назначения, где можно указать параметры пересылки событий.
- Укажите параметры в закладке Основные параметры:
- В раскрывающемся списке Точка назначения выберите Создать.
- Введите в поле Название уникальное имя для точки назначения. Название должно содержать от 1 до 128 символов в кодировке Unicode.
- С помощью переключателя Выключено, выберите, будут ли события отправляться в эту точку назначения. По умолчанию отправка событий включена.
- Выберите Тип точки назначения:
- Выберите storage, если хотите настроить отправку обработанных событий в хранилище.
- Выберите correlator, если хотите настроить отправку обработанных событий в коррелятор.
- Выберите nats-jetstream, tcp, http, kafka или file, если хотите настроить отправку событий в другие места.
- Укажите URL, куда следует отправлять события, в формате hostname:<порт API>.
Для всех типов, кроме nats-jetstream, file и diode с помощью кнопки URL можно указать несколько адресов отправки.
- Для типов nats-jetstream и kafka в поле Топик укажите, в какой топик должны записываться данные. Топик должен содержать символы в кодировке Unicode.Топик для Kafka имеет ограничение на длину в 255 символов.
- При необходимости укажите параметры в закладке Дополнительные параметры. Доступные параметры зависят от выбранного типа точки назначения:
- Сжатие – раскрывающийся список, в котором можно включить сжатие Snappy. По умолчанию сжатие Выключено.
- Прокси-сервер – раскрывающийся список для выбора прокси-сервера.
- Размер буфера – поле, в котором можно указать размер буфера (в байтах) для точки назначения. Значение по умолчанию: 1 МБ; максимальное: 64 МБ.
- Время ожидания – поле, в котором можно указать время ожидания (в секундах) ответа другого сервиса или компонента. Значение по умолчанию:
30. - Размер дискового буфера – поле, в котором можно указать размер дискового буфера в байтах. По умолчанию размер равен 10 ГБ.
- Идентификатор кластера – идентификатор кластера NATS.
- Режим TLS – раскрывающийся список, в котором можно указать условия использование шифрования TLS:
- Выключено (по умолчанию) – не использовать шифрование TLS.
- Включено – использовать шифрование, но без верификации.
- С верификацией – использовать шифрование с верификацией сертификата, подписанного корневым сертификатом KUMA. Корневой сертификат и ключ KUMA создаются автоматически при установке программы и располагаются на сервере Ядра KUMA в папке /opt/kaspersky/kuma/core/certificates/.
При использовании TLS невозможно указать IP-адрес в качестве URL.
- Политика выбора URL – раскрывающийся список, в котором можно выбрать способ определения, на какой URL следует отправлять события, если URL было указано несколько:
- Любой – события отправляются в один из доступных URL до тех пор, пока этот URL принимает события. При разрыве связи (например, при отключении принимающего узла) для отправки событий будет выбран другой URL.
- Сначала первый – события отправляются в первый URL из списка добавленных адресов. Если он становится недоступен, события отправляются в следующий по очереди доступный узел. Когда первый URL снова становится доступен, события снова начинаются отправляться в него.
- По очереди – пакеты с событиями по очереди отправляться в доступные URL из списка. Поскольку пакеты отправляются или при переполнении буфера точки назначения, или при срабатывании таймера очистки буфера, эта политика выбора URL не гарантирует равное распределение событий по точкам назначения.
- Разделитель – этот раскрывающийся список используется для указания символа, определяющего границу между событиями. По умолчанию используется
\n. - Путь – путь к файлу, если выбран тип точки назначения file.
- Интервал очистки буфера – это поле используется для установки времени (в секундах) между отправкой данных в точку назначения. Значение по умолчанию:
100. - Рабочие процессы – это поле используется для установки количества служб, обрабатывающих очередь. Значение по умолчанию равно количеству vCPU сервера, на котором установлено Ядро KUMA.
- Вы можете установить проверки работоспособности, используя поля Путь проверки работоспособности и Ожидание проверки работоспособности. Вы также можете отключить проверку работоспособности, установив флажок Проверка работоспособности отключена.
- Отладка – раскрывающийся список, в котором можно указать, будет ли включено логирование ресурса. По умолчанию указывается значение Выключено.
- С помощью раскрывающегося списка Дисковый буфер можно включить или выключить использование дискового буфера. По умолчанию дисковый буфер отключен.
Дисковый буфер используется, если коллектор не может направить в точку назначения нормализованные события. Объём выделенного дискового пространства ограничен значением параметра Размер дискового буфера.
Если выделенное под дисковый буфер дисковое пространство исчерпано, события ротируются по следующему принципу: новые события замещают самые старые события, записанные в буфер.
- В разделе Фильтр можно задать условия определения событий, которые будут обрабатываться этим ресурсом. В раскрывающемся списке можно выбрать существующий фильтр или Создать новый фильтр.
- В раскрывающемся списке Фильтр выберите Создать.
- Если вы хотите сохранить фильтр в качестве отдельного ресурса, установите флажок Сохранить фильтр.
В этом случае вы сможете использовать созданный фильтр в разных сервисах.
По умолчанию флажок снят.
- Если вы установили флажок Сохранить фильтр, в поле Название введите название для создаваемого ресурса фильтра. Название должно содержать от 1 до 128 символов в кодировке Unicode.
- В блоке параметров Условия задайте условия, которым должны соответствовать события:
- Нажмите на кнопку Добавить условие.
- В раскрывающихся списках Левый операнд и Правый операнд укажите параметры поиска.
В зависимости от источника данных, выбранного в поле Правый операнд, могут отобразиться поля дополнительных параметров, с помощью которых вам нужно определить значение, которое будет передано в фильтр. Например, при выборе варианта активный лист потребуется указать название активного листа, ключ записи и поле ключа записи.
- В раскрывающемся списке оператор выберите нужный вам оператор.
- При необходимости установите флажок без учета регистра. В этом случае оператор игнорирует регистр значений.
Действие флажка не распространяется на операторы InSubnet, InActiveList, InCategory, InActiveDirectoryGroup.
По умолчанию флажок снят.
- Если вы хотите добавить отрицательное условие, в раскрывающемся списке Если выберите Если не.
- Вы можете добавить несколько условий или группу условий.
- Если вы добавили несколько условий или групп условий, выберите условие отбора (и, или, не), нажав на кнопку И.
- Если вы хотите добавить уже существующие фильтры, которые выбираются в раскрывающемся списке Выберите фильтр, нажмите на кнопку Добавить фильтр.
Параметры вложенного фильтра можно просмотреть, нажав на кнопку
.
- Нажмите Сохранить.
Созданная точка назначения отображается в закладке мастера установки. Точку назначения можно удалить из набора ресурсов, выбрав ее и в открывшемся окне нажав Удалить.
Перейдите к следующему шагу мастера установки.
В началоШаг 8. Проверка параметров
Это обязательный и заключительный шаг мастера установки. На этом шаге в KUMA создается набор ресурсов для сервиса и на основе этого набора автоматически создаются сервисы:
- Набор ресурсов для коллектора отображается в разделе Ресурсы → Коллекторы. Его можно использовать для создания новых сервисов коллектора. При изменении этого набора ресурсов все сервисы, которые работают на его основе, будут использовать новые параметры, если сервисы перезапустить: для этого можно использовать кнопки Сохранить и перезапустить сервисы и Сохранить и обновить параметры сервисов.
Набор ресурсов можно изменять, копировать, переносить из папки в папку, удалять, импортировать и экспортировать, как другие ресурсы.
- Сервисы отображаются в разделе Ресурсы → Активные сервисы. Созданные с помощью мастера установки сервисы выполняют функции внутри программы KUMA – для связи с внешними частями сетевой инфраструктуры необходимо установить аналогичные внешние сервисы на предназначенных для них серверах и устройствах. Например, внешний сервис коллектора следует установить на сервере, предназначенном для получения событий; внешние сервисы хранилища – на серверах с развернутой службой ClickHouse; внешние сервисы агентов – на тех устройствах Windows, где требуется получать и откуда необходимо пересылать события Windows.
Чтобы завершить мастер установки:
- Нажмите Сохранить и создать сервис.
В закладке мастера установки Проверка параметров отображается таблица сервисов, созданных на основе набора ресурсов, выбранных в мастере установки. В нижней части окна отображаются примеры команд, с помощью которых необходимо установить внешние аналоги этих сервисов на предназначенные для них серверы и устройства.
Например:
/opt/kaspersky/kuma/kuma collector --core https://kuma-example:<порт, используемый для связи с Ядром KUMA> --id <идентификатор сервиса> --api.port <порт, используемый для связи с сервисом> --install
Файл kuma можно найти внутри установщика в директории /kuma-ansible-installer/roles/kuma/files/.
Порт для связи с Ядром KUMA, идентификатор сервиса и порт для связи с сервисом добавляются в команду автоматически. Также следует убедиться в сетевой связности системы KUMA и при необходимости открыть используемые ее компонентами порты.
- Закройте мастер, нажав Сохранить коллектор.
Сервис коллектора создан в KUMA. Теперь аналогичный сервис необходимо установить на сервере, предназначенном для получения событий.
Если в коллекторы был выбран коннектор типа wmi или wec, потребуется также установить автоматически созданные агенты KUMA.
В началоУстановка коллектора в сетевой инфраструктуре KUMA
Коллектор состоит из двух частей: одна часть создается внутри веб-интерфейса KUMA, а другая устанавливается на сервере сетевой инфраструктуры, предназначенной для получения событий. В сетевой инфраструктуре устанавливается вторая часть коллектора.
Чтобы установить коллектор:
- Войдите на сервер, на котором вы хотите установить сервис.
- Создайте директорию /opt/kaspersky/kuma/.
- Поместите в директорию /opt/kaspersky/kuma/ файл kuma, расположенный внутри установщика в директории /kuma-ansible-installer/roles/kuma/files/.
Убедитесь, что файл kuma имеет достаточные права для запуска. Если файл не является исполняемым, измените права для запуска с помощью следующей команды:
sudo chmod +x /opt/kaspersky/kuma/kuma - Поместите в директорию /opt/kaspersky/kuma/ файл LICENSE из /kuma-ansible-installer/roles/kuma/files/ и примите лицензию, выполнив следующую команду:
sudo /opt/kaspersky/kuma/kuma license - Создайте пользователя kuma:
sudo useradd --system kuma && usermod -s /usr/bin/false kuma - Выдайте пользователю kuma права на директорию /opt/kaspersky/kuma и все файлы внутри директории:
sudo chown -R kuma:kuma /opt/kaspersky/kuma/ - Выполните следующую команду:
sudo /opt/kaspersky/kuma/kuma collector --core https://<FQDN сервера Ядра KUMA>:<порт, используемый Ядром KUMA для внутренних коммуникаций (по умолчанию используется порт 7210)> --id <идентификатор сервиса, скопированный из веб-интерфейса KUMA> --api.port <порт, используемый для связи с устанавливаемым компонентом>Пример:
sudo /opt/kaspersky/kuma/kuma collector --core https://test.kuma.com:7210 --id XXXX --api.port YYYYЕсли в результате выполнения команды были выявлены ошибки, проверьте корректность параметров. Например, наличие требуемого уровня доступа, сетевой доступности между сервисом коллектора и ядром, уникальность выбранного API-порта. После устранения ошибок продолжите установку коллектора.
Если ошибки не выявлены, а статус коллектора в веб-интерфейсе KUMA изменился на зеленый, остановите выполнение команды и перейдите к следующему шагу.
Команду можно скопировать на последнем шаге мастера установщика. В ней автоматически указывается адрес и порт сервера Ядра KUMA, идентификатор устанавливаемого коллектора, а также порт, который этот коллектор использует для связи.
При развертывании нескольких сервисов KUMA на одном хосте в процессе установки необходимо указать уникальные порты для каждого компонента с помощью параметра
--api.port <порт>. По умолчанию используется значение--api.port 7221.Перед установкой необходимо убедиться в сетевой связности компонентов KUMA.
- Выполните команду повторно, добавив ключ
--install:sudo /opt/kaspersky/kuma/kuma collector --core https://<FQDN сервера Ядра KUMA>:<порт, используемый Ядром KUMA для внутренних коммуникаций (по умолчанию используется порт 7210)> --id <идентификатор сервиса, скопированный из веб-интерфейса KUMA> --api.port <порт, используемый для связи с устанавливаемым компонентом> --installПример:
sudo /opt/kaspersky/kuma/kuma collector --core https://kuma.example.com:7210 --id XXXX --api.port YYYY --install - Добавьте порт коллектора KUMA в исключения брандмауэра.
Для правильной работы программы убедитесь, что компоненты KUMA могут взаимодействовать с другими компонентами и программами по сети через протоколы и порты, указанные во время установки компонентов KUMA.
Коллектор установлен. С его помощью можно получать и передавать на обработку данные из источника события.
В началоПроверка правильности установки коллектора
Проверить готовность коллектора к получению событий можно следующим образом:
- В веб-интерфейсе KUMA откройте раздел Ресурсы → Активные сервисы.
- Убедитесь, что у установленного вами коллектора зеленый статус.
Если статус коллектора отличается от зеленого, просмотрите журнал этого сервиса на машине, где он установлен, в директории /opt/kaspersky/kuma/collector/<идентификатор корректора>/log/collector. Ошибки записываются в журнал вне зависимости от того, включен или выключен режим отладки.
Если коллектор установлен правильно и вы уверены, что из источника событий приходят данные, то при поиске связанных с ним событий в таблице должны отображаться события.
Чтобы проверить наличие ошибок нормализации с помощью раздела События веб-интерфейса KUMA:
- Убедитесь, что запущен сервис коллектора.
- Убедитесь, что источник событий передает события в KUMA.
- Убедитесь, что в разделе Ресурсы веб-интерфейса KUMA в раскрывающемся списке Хранить исходное событие ресурса Нормализатор выбрано значение При возникновении ошибок.
- В разделе События в KUMA выполните поиск событий со следующими параметрами:
ServiceID = <идентификатор коллектора, который требуется проверить>Raw != ""
Если при этом поиске будут обнаружены какие-либо события, это означает, что есть ошибки нормализации, и их необходимо исследовать.
Чтобы проверить наличие ошибок нормализации с помощью панели мониторинга Grafana:
- Убедитесь, что запущен сервис коллектора.
- Убедитесь, что источник событий передает события в KUMA.
- Откройте раздел Метрики и перейдите по ссылке KUMA Collectors.
- Проверьте, отображаются ли ошибки в разделе Errors (Ошибки) виджета Normalization (Нормализация).
Если в результате обнаружены ошибки нормализации, их необходимо исследовать.
В коллекторах типа WEC и WMI необходимо убедиться, что для подключения к агенту используется уникальный порт. Этот порт указывается в разделе Транспорт мастера установки коллектора.
В началоОбеспечение бесперебойной работы коллекторов
Бесперебойное поступление событий от источника событий в KUMA является важным условием защиты сетевой инфраструктуры. Бесперебойность можно обеспечить автоматическим перенаправлением потока событий на большее число коллекторов:
- На стороне KUMA необходимо установить два или больше одинаковых коллекторов.
- На стороне источника событий необходимо настроить управление потоками событий между коллекторами с помощью сторонних средств управления нагрузкой серверов, например rsyslog или nginx.
При такой конфигурации коллекторов поступающие события не будут теряться, когда сервер коллектора по какой-либо причине недоступен.
Необходимо учитывать, что при переключении потока событий между коллекторами агрегация событий будет происходить на каждом коллекторе отдельно.
Если коллектор KUMA не удается запустить, а в его журнале выявлена ошибка "panic: runtime error: slice bounds out of range [8:0]":
- Остановите коллектор.
sudo systemctl stop kuma-collector-<идентификатор коллектора> - Удалите файлы с кэшем DNS-обогащения.
sudo rm -rf /opt/kaspersky/kuma/collector/<идентификатор коллектора>/cache/enrichment/DNS-* - Удалите файлы с кэшем событий (дисковый буфер). Выполняйте команду, только если можно пожертвовать событиями, находящимися в дисковых буферах коллектора.
sudo rm -rf /opt/kaspersky/kuma/collector/<идентификатор коллектора>/buffers/* - Запустите сервис коллектора.
sudo systemctl start kuma-collector-<идентификатор коллектора>
Управление потоком событий с помощью rsyslog
Чтобы включить управление потоками событий на сервере источника событий с помощью rsyslog:
- Создайте два или более одинаковых коллекторов, с помощью которых вы хотите обеспечить бесперебойный прием событий.
- Установите на сервере источника событий rsyslog (см. документацию rsyslog).
- Добавьте в конфигурационный файл /etc/rsyslog.conf правила перенаправления потока событий между коллекторами:
*.* @@<FQDN основного сервера коллектора>:<порт, на который коллектор принимает события>$ActionExecOnlyWhenPreviousIsSuspended on& @@<FQDN резервного сервера коллектора>:<порт, на который коллектор принимает события>$ActionExecOnlyWhenPreviousIsSuspended off - Перезапустите rsyslog, выполнив команду:
systemctl restart rsyslog.
Управление потоками событий на сервере источника событий включено.
В началоУправление потоком событий с помощью nginx
Для управления потоком событий средствами nginx необходимо создать и настроить ngnix-сервер, который будет принимать события от источника событий, а затем перенаправлять их на коллекторы.
Чтобы включить управление потоками событий на сервере источника событий с помощью nginx:
- Создайте два или более одинаковых коллекторов, с помощью которых вы хотите обеспечить бесперебойный прием событий.
- Установите nginx на сервере, предназначенном для управления потоком событий.
- Команда для установки в Oracle Linux 8.6:
$sudo dnf install nginx - Команда для установки в Ubuntu 20.4:
$sudo apt-get install nginxПри установке из sources, необходимо собрать с параметром
-with-stream:$sudo ./configure -with-stream -without-http_rewrite_module -without-http_gzip_module
- Команда для установки в Oracle Linux 8.6:
- На nginx-сервере в конфигурационный файл nginx.conf добавьте модуль stream с правилами перенаправления потока событий между коллекторами.
- Перезапустите nginx, выполнив команду:
systemctl restart nginx - На сервере источника событий перенаправьте события на ngnix-сервер.
Управление потоками событий на сервере источника событий включено.
Для тонкой настройки балансировки может потребоваться nginx Plus, однако некоторые методы балансировки, например Round Robin и Least Connections, доступны в базовой версии ngnix.
Подробнее о настройке nginx см. в документации nginx.
В начало