Мониторинг сервисов
Вы можете использовать следующие возможности, чтобы отслеживать состояние всех сервисов, кроме холодного хранилища и агента:
- Просматривать алерты Victoria Metrics.
Пользователи с ролью Главный администратор могут настраивать пороговые значения параметров сервисов KUMA и если заданные пороговые значения будут превышены, произойдут следующие изменения:
- KUMA зарегистрирует событие аудита Зарегистрирован алерт Victoria Metrics для сервиса.
- KUMA отправит уведомление Главному администратору по электронной почте.
- Сервисы будут отображаться в разделе Активные сервисы в желтом статусе. Если вы наведете курсор на значок статуса, сообщение об ошибке будет доступно для просмотра.
- Просматривать метрики Victoria Metrics при условии наличия у пользователя роли с правами доступа к метрикам.
В следующих примерах показано, каким образом вы можете отслеживать состояние сервисов.
- Если в разделе Активные сервисы сервис коллектора находится в желтом статусе и вы видите сообщение Enrichment errors increasing, вы можете выполнить следующие действия:
- Перейти в раздел KUMA Метрики → <тип сервиса> → <имя сервиса> → Enrichment → Errors для сервиса в желтом статусе, выяснить, какое именно обогащение работает с ошибками, и просмотреть график, чтобы уточнить когда именно началась проблема и отследить динамику.
- Поскольку вероятной причиной ошибок обогащения может быть недоступность DNS-сервера или ошибки обогащения CyberTrace, вы можете проверить параметры подключения DNS или CyberTrace.
- Если в разделе Активные сервисы сервис коллектора находится в желтом статусе и вы видите сообщение Output Event Loss increasing, вы можете выполнить следующие действия:
- Перейти в раздел KUMA Метрики → <тип сервиса> → <имя сервиса> → IO → Output Event Loss для сервиса в желтом статусе и просмотреть график, чтобы уточнить когда именно началась проблема и отследить динамику.
- Поскольку вероятной причиной потери событий может быть превышение размера буфера или недоступность точки назначения, вы можете проверить доступность и правильность подключения точки назначения или выяснить, почему превышен размер буфера.
Настройка параметров мониторинга сервисов
Чтобы настроить параметры сервисов:
- В веб-консоли KUMA перейдите в раздел Параметры → Мониторинг сервисов.
- Укажите значения параметров мониторинга для сервисов.
Мониторинг сервисов не распространяется на холодное хранилище.
Если вы указали некорректное значение, которое не подходит по диапазону или формату, значение будет сброшено до ранее установленного.
- Нажмите Сохранить.
После сохранения параметров KUMA регистрирует аудит событие Пороговые значение параметров мониторинга сервисов изменены.
KUMA отслеживает состояние сервисов по заданным параметрам.
В разделе Активные сервисы вы можете отфильтровать сервисы по статусам или указать в поле поиска слово из текста ошибки, например "QPS" или "buffer", и нажать ENTER. В результате будет список сервисов с ошибками. Использование специальных символы ", },{, для поиска недопустимо, результаты будут нерелевантны.
Отключение мониторинга сервисов
Чтобы отключить мониторинг сервисов:
- В веб-консоли KUMA перейдите в раздел Параметры → Мониторинг сервисов.
- Если вы хотите отключить мониторинг сервисов только для коллекторов, в окне Мониторинг сервисов. Настройка пороговых значений в блоке параметров Коллекторы установите флажок Отключить ошибки коннекторов.
В результате будет отключен только анализ метрики Connector errors для коллекторов.
- Если вы хотите отключить мониторинг всех сервисов, в окне Мониторинг сервисов. Настройка пороговых значений установите флажок Выключить.
Мониторинг сервисов KUMA будет отключен, при этом сервисам не будет присваиваться желтый статус.
Просмотр метрик KUMA
Для отслеживания работы своих компонентов, потока событий, контекста корреляции в KUMA выполняется сбор и хранение большого количества параметров. Для сбора, хранения и анализа параметров используется решение VictoriaMetrics, представляющее собой СУБД в формате временных рядов. Визуализация собранных метрик осуществляется с помощью Grafana. В разделе KUMA → Meтрики представлены панели мониторинга с визуализацией ключевых параметров работы различных компонентов KUMA.
Сервис Ядра KUMA выполняет настройку параметров VicrtoriaMectics и Grafana автоматически, участие пользователя не требуется.
Визуализация собранных метрик осуществляется с помощью решения Grafana. RPM-пакет службы kuma-core формирует конфигурацию Grafana и создает отдельную панель мониторинга для визуализации метрик каждого сервиса. Графики в разделе Метрики появляются с задержкой около 1,5 минут.
Полная информация о метриках доступна в разделе Метрики веб-интерфейса KUMA. При выборе этого раздела открывается автоматически обновляемый портал Grafana, развернутый во время установки Ядра. Если в разделе Метрики вы видите core:<номер порта>, это означает, что KUMA развернута в отказоустойчивой конфигурации и метрики получены с хоста, на котором было установлено Ядро. В прочих конфигурациях отображается имя хоста, с которого KUMA получает метрики.
Метрики коллекторов
Название метрики |
Описание |
|---|---|
IO (ввод-вывод) – метрики, относящиеся к вводу и выводу сервиса. |
|
Processing EPS (обрабатываемые события в секунду) |
Количество событий, обработанных за секунду. |
Output EPS (вывод событий) |
Количество событий, отправленных точке назначения за секунду. |
Output Latency (задержка вывода) |
Время в миллисекундах, затраченное на отправку пакета событий точке назначения и получение от нее ответа. Отображается медиана. |
Output Errors (ошибки вывода) |
Количество ошибок, возникших за секунду при отправке пакетов событий точке назначения. Сетевые ошибки и ошибки записи в дисковый буфер точки назначения отображаются отдельно. |
Output Event Loss (потеря событий) |
Количество событий, потерянных за секунду. События могут быть потеряны из-за сетевых ошибок или ошибок записи в дисковый буфер точки назначения. События также теряются, если точка назначения отвечает кодом ошибки, например при недействительном запросе. |
Output Disk Buffer SIze (размер дискового буфера) |
Размер дискового буфера коллектора, связанного с точкой назначения, в байтах. Если отображается ноль, в дисковой буфер коллектора не помещен ни один пакет событий, и сервис работает правильно. |
Write Network BPS (байты, принятые в сеть) |
Количество байт, принятых в сеть за секунду. |
Connector errors (ошибки коннектора) |
Количество ошибок в логах коннектора. |
Normalization (нормализация) – метрики, относящиеся к нормализаторам. |
|
Raw & Normalized event size (размер сырых и нормализованных событий) |
Размер необработанного и нормализованного событий. Отображается медиана. |
Errors (ошибки) |
Количество ошибок нормализации, возникших за секунду. |
Filtration (фильтрация) – метрики, относящиеся к фильтрам. |
|
EPS (события, обрабатываемые за секунду) |
Количество событий, удовлетворяющих условиям фильтра и отправленных в обработку за секунду. Коллектор обрабатывает события, удовлетворяющие условиям фильтра, только если пользователь добавил фильтр в конфигурацию сервиса коллектора. |
Aggregation (агрегация) – показатели, относящиеся к правилам агрегации. |
|
EPS (события, обрабатываемые в секунду) |
Количество событий, полученных и созданных правилом агрегации за секунду. Эта метрика помогает определить эффективность правил агрегации. |
Buckets (контейнеры) |
Количество контейнеров в правиле агрегации. |
Enrichment (обогащение) – метрики, относящиеся к правилам обогащения. |
|
Cache RPS (запросы к кешу в секунду) |
Количество запросов, отправленных локальному кешу за секунду. |
Source RPS (запросы к источнику в секунду) |
Количество запросов, отправленных источнику обогащения, например словарю, за секунду. |
Source Latency (задержка источника) |
Время в миллисекундах, затраченное на отправку запроса источнику обогащения и получение от него ответа. Отображается медиана. |
Queue (очередь) |
Размер очереди запросов на обогащение. Эта метрика помогает найти "узкие места" в правилах обогащения. |
Errors (ошибки) |
Количество ошибок, возникших за секунду при отправке запросов источнику обогащения. |
Метрики корреляторов
Название метрики |
Описание |
|---|---|
IO (ввод-вывод) – метрики, относящиеся к вводу и выводу сервиса. |
|
Processing EPS (обрабатываемые события в секунду) |
Количество событий, обработанных за секунду. |
Output EPS (вывод событий) |
Количество событий, отправленных точке назначения за секунду. |
Output Latency (задержка вывода) |
Время в миллисекундах, затраченное на отправку пакета событий точке назначения и получение от нее ответа. Отображается медиана. |
Output Errors (ошибки вывода) |
Количество ошибок, возникших за секунду при отправке пакетов событий точке назначения. Сетевые ошибки и ошибки записи в дисковый буфер точки назначения отображаются отдельно. |
Output Event Loss (потеря событий) |
Количество событий, потерянных за секунду. События могут быть потеряны из-за сетевых ошибок или ошибок записи в дисковый буфер точки назначения. События также теряются, если точка назначения отвечает кодом ошибки, например при недействительном запросе. |
Output Disk Buffer SIze (размер дискового буфера) |
Размер дискового буфера коллектора, связанного с точкой назначения, в байтах. Если отображается ноль, в дисковой буфер коллектора не помещен ни один пакет событий, и сервис работает правильно. |
Correlation (корреляция) – метрики, относящиеся к правилам корреляции. |
|
EPS (события, обрабатываемые в секунду) |
Количество корреляционных событий, созданных правилом корреляции за секунду. |
Buckets (контейнеры) |
Количество контейнеров в правиле корреляции стандартного типа. |
Rate Limiter Hits (лимит срабатываний) |
Количество превышений правилом корреляции лимита срабатываний за секунду. |
Active Lists OPS (запросы к активному листу в секунду) |
Количество запросов на выполнение операций, отправленных активному листу за секунду, и сами операции. |
Active Lists Records (записи в активном листе) |
Количество записей в активном листе. |
Active Lists On-Disk Size (размер на диске) |
Размер активного листа на диске в байтах. |
Enrichment (обогащение) – метрики, относящиеся к правилам обогащения. |
|
Cache RPS (запросы к кешу в секунду) |
Количество запросов, отправленных локальному кешу за секунду. |
Source RPS (запросы к источнику в секунду) |
Количество запросов, отправленных источнику обогащения, например словарю, за секунду. |
Source Latency (задержка источника) |
Время в миллисекундах, затраченное на отправку запроса источнику обогащения и получение от него ответа. Отображается медиана. |
Queue (очередь) |
Размер очереди запросов на обогащение. Эта метрика помогает найти "узкие места" в правилах обогащения. |
Errors (ошибки) |
Количество ошибок, возникших за секунду при отправке запросов источнику обогащения. |
Response (ответ) – метрики, относящиеся к правилам реагирования. |
|
RPS (запросы в секунду) |
Количество активаций правила реагирования за секунду. |
Метрики хранилища
Название метрики |
Описание |
|---|---|
Clickhouse / General (общие параметры) – метрики, относящиеся к общим параметрам кластера ClickHouse. |
|
Active Queries (активные запросы) |
Количество выполняемых запросов, отправленных кластеру ClickHouse. Эта метрика отображается для каждого экземпляра ClickHouse. |
QPS (запросы в секунду) |
Количество запросов, отправленных кластеру ClickHouse за секунду. |
Failed QPS (безуспешные запросы в секунду) |
Количество безуспешных запросов, отправленных кластеру ClickHouse за секунду. |
Allocated memory (назначенная память) |
Количество RAM в гигабайтах, назначенное процессу ClickHouse. |
Clickhouse / Insert (вставка) – метрики, относящиеся к вставке событий в экземпляр ClickHouse. |
|
Insert EPS (вставка событий) |
Количество событий, вставленных в экземпляр ClickHouse за секунду. |
Insert QPS (запросы на вставку в секунду) |
Количество запросов на вставку событий в экземпляр ClickHouse, отправленных кластеру ClickHouse за секунду. |
Failed Insert QPS (безуспешные запросы на вставку в секунду) |
Количество безуспешных запросов на вставку событий в экземпляр ClickHouse, отправленных кластеру ClickHouse за секунду. |
Delayed Insert QPS (отложенные запросы на вставку в секунду) |
Количество отложенных запросов на вставку событий в экземпляр ClickHouse, отправленных кластеру ClickHouse за секунду. Запросы были отложены узлом ClickHouse из-за превышения мягкого лимита активных слияний. |
Rejected Insert QPS (отклоненные запросы на вставку в секунду) |
Количество отклоненных запросов на вставку событий в экземпляр ClickHouse, отправленных кластеру ClickHouse за секунду. Запросы были отклонены узлом ClickHouse из-за превышения жесткого лимита активных слияний. |
Active Merges (активные слияния) |
Количество активных слияний. |
Distribution Queue (очередь распределения) |
Количество временных файлов с событиями, которые не удалось вставить в экземпляр ClickHouse из-за того, что он был недоступен. Эти события невозможно найти с помощью поиска. |
Clickhouse / Select (выборка) – метрики, относящиеся к выборке событий в экземпляре ClickHouse. |
|
Select QPS (запросы на выборку в секунду) |
Количество запросов на выборку событий в экземпляре ClickHouse, отправленных кластеру ClickHouse за секунду. |
Failed Select QPS (безуспешные запросы на выборку в секунду) |
Количество безуспешных запросов на выборку событий в экземпляре ClickHouse, отправленных кластеру ClickHouse за секунду. |
Clickhouse / Replication (репликация) – метрики, относящиеся к репликам узлов ClickHouse. |
|
Active Zookeeper Connections (активные подключения к Zookeeper) |
Количество активных подключений к узлам кластера Zookeeper. При нормальной работе это число должно быть равным количеству узлов кластера Zookeeper. |
Read-only Replicas (реплики read-only) |
Количество реплик узлов ClickHouse в режиме read-only. При нормальной работе таких реплик узлов ClickHouse быть не должно. |
Active Replication Fetches (активные процессы скачивания) |
Количество активных процессов скачивания данных с узла ClickHouse при репликации данных. |
Active Replication Sends (активные процессы отправки) |
Количество активных процессов отправки данных узлу ClickHouse при репликации данных. |
Active Replication Consistency Checks (активные процессы проверки консистентности) |
Количество активных проверок консистентности данных на репликах узлов ClickHouse при репликации данных. |
Clickhouse / Networking (сеть) – метрики, относящиеся к сети кластера ClickHouse. |
|
Active HTTP Connections (активные HTTP-подключения) |
Количество активных подключений к HTTP-серверу кластера ClickHouse. |
Active TCP Connections (активные TCP-подключения) |
Количество активных подключений к TCP-серверу кластера ClickHouse. |
Active Interserver Connections (активные подключения между серверами) |
Количество активных служебных подключений между узлами ClickHouse. |
Метрики Ядра
Название метрики |
Описание |
|---|---|
Raft – метрики, относящиеся к чтению и обновлению состояния Ядра. |
|
Lookup RPS (запросы на чтение в секунду) |
Количество запросов на выполнение процедур чтения, отправленных Ядру за секунду, и сами процедуры. |
Lookup Latency (время обработки запроса на чтение) |
Время в миллисекундах, затраченное на выполнение процедур чтения, и сами процедуры. Отображается время для 99-ого процентиля процедур чтения. Один процент процедур чтения может выполняться дольше. |
Propose RPS (запросы на обновление состояния в секунду) |
Количество запросов на выполнение процедур обновления состояния, отправленных Ядру за секунду, и сами процедуры. |
Propose Latency (время обработки запроса на обновление состояния) |
Время в миллисекундах, затраченное на выполнение процедур обновления состояния, и сами процедуры. Отображается время для 99-ого процентиля процедур обновления состояния. Один процент процедур обновления состояния может выполняться дольше. |
API – метрики, относящиеся к API-запросам. |
|
RPS (запросы в секунду) |
Количество API-запросов, отправленных Ядру за секунду. |
Latency (задержка) |
Время в миллисекундах, затраченное на обработку одного API-запроса к Ядру. Отображается медиана. |
Errors (ошибки) |
Количество ошибок, возникших за секунду при отправке API-запросов Ядру. |
Notification Feed (фид уведомлений) – метрики, относящиеся к активности пользователей. |
|
Subscriptions (подписки) |
Количество клиентов, подключенных к Ядру через SSE для получения сообщений сервера в реальном времени. Обычно это число равно количеству клиентов, использующих веб-интерфейс KUMA. |
Errors (ошибки) |
Количество ошибок, возникших за секунду при отправке уведомлений пользователям. |
Schedulers (планировщики) – метрики, относящиеся к задачам Ядра. |
|
Active (активные) |
Количество повторяющихся активных системных задач. Задачи, созданные пользователем, игнорируются. |
Latency (задержка) |
Время в миллисекундах, затраченное на выполнение задачи. Отображается медиана. |
Errors (ошибки) |
Количество ошибок, возникших за секунду при выполнении задач. |
Метрики агента KUMA
Название метрики |
Описание |
|---|---|
IO (ввод-вывод) – метрики, относящиеся к вводу и выводу сервиса. |
|
Processing EPS (обрабатываемые события в секунду) |
Количество событий, обработанных за секунду. |
Output EPS (вывод событий) |
Количество событий, отправленных точке назначения за секунду. |
Output Latency (задержка вывода) |
Время в миллисекундах, затраченное на отправку пакета событий точке назначения и получение от нее ответа. Отображается медиана. |
Output Errors (ошибки вывода) |
Количество ошибок, возникших за секунду при отправке пакетов событий точке назначения. Сетевые ошибки и ошибки записи в дисковый буфер точки назначения отображаются отдельно. |
Output Event Loss (потеря событий) |
Количество событий, потерянных за секунду. События могут быть потеряны из-за сетевых ошибок или ошибок записи в дисковый буфер точки назначения. События также теряются, если точка назначения отвечает кодом ошибки, например при недействительном запросе. |
Output Disk Buffer SIze (размер дискового буфера) |
Размер дискового буфера коллектора, связанного с точкой назначения, в байтах. Если отображается ноль, в дисковой буфер коллектора не помещен ни один пакет событий, и сервис работает правильно. |
Write Network BPS (байты, принятые в сеть) |
Количество байт, принятых в сеть за секунду. |
Метрики Event routers
Название метрики |
Описание |
|---|---|
IO (ввод-вывод) – метрики, относящиеся к вводу и выводу сервиса. |
|
Processing EPS (обрабатываемые события в секунду) |
Количество событий, обработанных за секунду. |
Output EPS (вывод событий) |
Количество событий, отправленных точке назначения за секунду. |
Output Latency (задержка вывода) |
Время в миллисекундах, затраченное на отправку пакета событий точке назначения и получение от нее ответа. Отображается медиана. |
Output Errors (ошибки вывода) |
Количество ошибок, возникших за секунду при отправке пакетов событий точке назначения. Сетевые ошибки и ошибки записи в дисковый буфер точки назначения отображаются отдельно. |
Output Event Loss (потеря событий) |
Количество событий, потерянных за секунду. События могут быть потеряны из-за сетевых ошибок или ошибок записи в дисковый буфер точки назначения. События также теряются, если точка назначения отвечает кодом ошибки, например при недействительном запросе. |
Output Disk Buffer SIze (размер дискового буфера) |
Размер дискового буфера коллектора, связанного с точкой назначения, в байтах. Если отображается ноль, в дисковой буфер коллектора не помещен ни один пакет событий, и сервис работает правильно. |
Write Network BPS (байты, принятые в сеть) |
Количество байт, принятых в сеть за секунду. |
Connector Errors (ошибки коннектора) |
Количество ошибок в журнале коннектора. |
Метрики, общие для всех сервисов
Название метрики |
Описание |
|---|---|
Process – общие метрики процесса. |
|
Memory (память) |
Использование RAM (RSS) в мегабайтах. |
DISK BPS (считанные/записанные байты диска) |
Количество байтов, считанных/записанных на диск за секунду. |
Network BPS (байты, принятые/переданные по сети) |
Количество байтов, принятых/переданных по сети за секунду. |
Network Packet Loss (потеря пакетов) |
Количество сетевых пакетов, потерянных за секунду. |
GC Latency (задержка сборщика мусора) |
Время в миллисекундах, затраченное на проведение цикла сборщика мусора GO (Garbage Collector). Отображается медиана. |
Goroutines (гоурутины) |
Количество активных гоурутин. Это число отличается от количества потоков операционной системы. |
OS (ОС) – метрики, относящиеся к операционной системе. |
|
Load (нагрузка) |
Средняя нагрузка. |
CPU (ЦП) |
Загрузка центрального процессора в процентах. |
Memory (память) |
Использование RAM (RSS) в процентах. |
Disk (диск) |
Использование дискового пространства в процентах. |
Срок хранения метрик
По умолчанию данные о работе KUMA хранятся 3 месяца. Этот срок можно изменить.
Чтобы изменить срок хранения метрик KUMA:
- Войдите в ОС сервера, на котором установлено Ядро KUMA.
- В файле /etc/systemd/system/multi-user.target.wants/kuma-victoria-metrics.service в параметре ExecStart измените флаг
--retentionPeriod=<срок хранения метрик в месяцах>, подставив нужный срок. Например,--retentionPeriod=4означает, что метрики будут храниться 4 месяца. - Перезапустите KUMA, выполнив последовательно следующие команды:
systemctl daemon-reloadsystemctl restart kuma-victoria-metrics
Срок хранения метрик изменен.
В началоУсловия срабатывания алертов по метрикам KUMA
Если значение метрики KUMA о работе сервиса превышает пороговое значение соответствующего параметра, настроенного в разделе KUMA Мониторинг сервисов, от решения VictoriaMetrics поступает алерт, и в статусе этого сервиса отображается сообщение об ошибке.
Получение алертов от VictoriaMetrics происходит со следующей периодичностью:
- VictoriaMetrics собирает информацию от сервисов KUMA каждые 15 секунд.
- VictoriaMetrics обновляет алерты для сервисов KUMA каждую минуту.
- Сервис Ядро KUMA собирает информацию от VictoriaMetrics каждые 15 секунд.
Таким образом общая длительность задержки в обновлении статуса сервиса может достигать не более 2-3 минут.
Если вы отключили получение алертов от VictoriaMetrics, некоторые сервисы KUMA все равно могут отображаться с желтым статусом. Это может произойти в следующих случаях:
- Для сервиса хранилище:
- если алерт пришел по API запросу в параметре /status от ClickHouse;
- если холодное хранилище сервиса Хранилище не проверяется.
- Для сервиса коллектор: если алерт пришел по API-запросу в параметре /status.
- Для сервиса коррелятор: если есть правило реагирования, для которого требуется модуль Advanced Responses, но этот модуль отсутствует в действующей лицензии или срок действия лицензии, в которой есть этот модуль, истек.
В таблице ниже представлена информация о том, какие сообщения об ошибке могут появиться в статусе сервиса при получении алерта от VictoriaMetrics и как и на основании каких метрик и параметров они рассчитываются. Подробнее о метриках KUMA, на основании которых могут сработать алерты VictoriaMetrics, см. Просмотр метрик KUMA.
Например, если в таблице Активные сервисы для сервиса отображается желтый статус и сообщение об ошибке High distribution queue (в таблице ниже – столбец "Сообщение об ошибке"), вы можете посмотреть данные в виджете Enrichment, метрика Distribution Queue (в таблице ниже – столбец "Метрики KUMA").
Описание сообщений об ошибках для сервисов KUMA
Сообщение об ошибке |
Настраиваемые параметры для алертов |
Метрика KUMA |
Описание |
|---|---|---|---|
|
Интервал/Окно QPS, минуты Порог QPS |
Clickhouse / General (общие параметры) → Failed QPS (безуспешные запросы в секунду) |
Сообщение об ошибке отображается, если значение метрики Failed QPS превышает заданное значение параметра Порог QPS в течение интервала времени, заданного параметром Интервал/Окно QPS, минуты. Например, если из 100 запросов от решения VictoriaMetrics к сервису 25 пришли безуспешные, а параметр Порог QPS равен 0.2, алерт рассчитывается следующим образом: (25 / 100) * 100 > 0.2 * 100 25% > 20% Так как процент безуспешных запросов больше, чем заданный порог, для сервиса отобразится сообщение об ошибке. |
|
Интервал/Окно расчета ошибочных вставок QPS, минуты Порог вставок QPS |
Clickhouse / Insert (вставка) → Failed Insert QPS (безуспешные запросы на вставку в секунду) |
Сообщение об ошибке отображается, если значение метрики Failed Insert QPS превышает заданное значение параметра Порог вставок QPS в течение интервала времени, заданного параметром Интервал/Окно расчета ошибочных вставок QPS, минуты. Например, если из 100 запросов от решения VictoriaMetrics к сервису 25 пришли безуспешные, а параметр Порог вставок QPS равен 0.2, алерт рассчитывается следующим образом: (25 / 100) * 100 > 0.2 * 100 25% > 20% Так как процент безуспешных запросов больше, чем заданный порог, для сервиса отобразится сообщение об ошибке. |
|
Порог очереди распределения Интервал/Окно расчета очереди распределения, минуты |
Clickhouse / Insert (вставка) → Distribution Queue (очередь распределения) |
Сообщение об ошибке отображается, если значение метрики Distribution Queue превышает заданное значение параметра Порог очереди распределения в течение интервала времени, заданного параметром Интервал/Окно расчета очереди распределения, минуты. |
|
Порог свободного места на диске |
OS (ОС) → Disk (диск) |
Сообщение об ошибке отображается, если размер свободного места на диске (в процентах) в значении метрики Disk меньше, чем задано в параметре Порог свободного места на диске. Например, сообщение об ошибке отобразится, если если раздел, на котором установлена KUMA, занимает все место на диске. |
|
Порог свободного места на разделе диска |
OS (ОС) → Disk (диск) |
Сообщение об ошибке отображается, если размер свободного места в разделе диска, с которым работает KUMA (в процентах), осталось меньше, чем задано в параметре Порог свободного места на разделе диска. Например, сообщение об ошибке отобразится в следующих случаях:
|
|
Потери исходящих событий |
IO (ввод-вывод) → Output Event Loss (потеря событий) |
Сообщение об ошибке отображается, если значение метрики Output Event Loss возрастает в течение одной минуты. Вы можете включить или выключить отображение этого сообщения об ошибке с помощью параметра Потери исходящих событий. |
|
Интервал/Окно увеличения дискового буфера, минуты |
IO (ввод-вывод) → Output Disk Buffer Size (размер дискового буфера) |
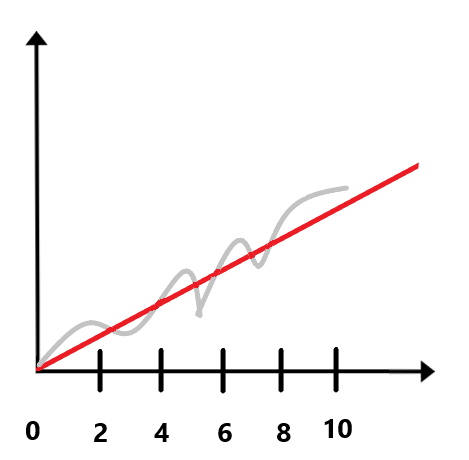
Сообщение об ошибке отображается, если в течение 10 минут с интервалом, заданным параметром Интервал/Окно увеличения дискового буфера, минуты, значение метрики Output Disk Buffer Size монотонно возрастает. Например, при значении параметра Интервал/Окно увеличения дискового буфера, минуты равном 2 минуты сообщение об ошибке отобразится, если в течение 10 минут размер дискового буфера будет монотонно возрастать каждые 2 минуты (см. рис. ниже).
|
|
Интервал/Окно увеличения очереди обогащения, минуты |
Enrichment (обогащение) → Queue (очередь) |
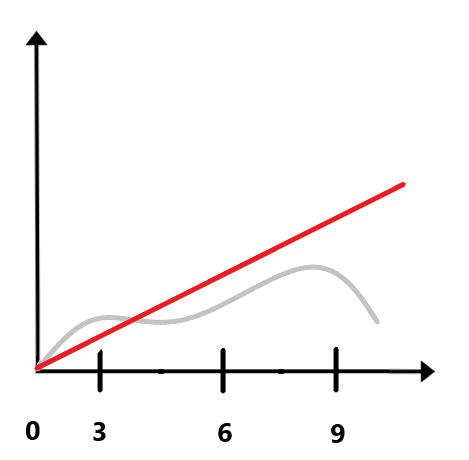
Сообщение об ошибке отображается, если в течение 10 минут с интервалом, заданным параметром Интервал/Окно увеличения очереди обогащения, минуты, значение метрики Queue монотонно возрастает. Например, при значении параметра Интервал/Окно увеличения очереди обогащения, минуты равном 3 минуты сообщение об ошибке отобразится, если в течение 10 минут очередь обогащения будет монотонно возрастать каждые три минуты. В случае, изображенном на рисунке ниже, сообщение об ошибке не отобразится, так как на девятой минуте значение метрики уменьшилось, поэтому последовательного монотонного возрастания нет.
|
|
Ошибки обогащения |
Enrichment (обогащение) → Errors (ошибки) |
Сообщение об ошибке отображается, если значение метрики Errors (количество ошибок) возрастает в течение одной минуты. Вы можете включить или выключить отображение этого сообщения об ошибке с помощью параметра Ошибки обогащения. |
|
Отключить ошибки коннекторов |
IO (ввод-вывод) → Connector Errors (ошибки коннектора) |
Сообщение об ошибке отображается, если значение метрики Connector Errors (количество ошибок) возрастает между последовательными опросами метрики решением VictoriaMetrics в течение одной минуты. Вы можете включить или выключить отображение этого сообщения об ошибке с помощью параметра Отключить ошибки коннекторов. |